Общий обзор программного обеспечения Justin компании JAVAD GNSS, предназначенного для решения широкого круга геодезических задач, уже появлялся на страницах журнала «Геопрофи» (см. № 3-2011). В данной статье хотелось бы остановиться на особенностях постобработки статических и кинематических измерений и алгоритмах, помогающих улучшить решение, в случае, когда наблюдения выполнялись при неблагоприятных условиях («экранирование», отражение сигнала от окружающих объектов, недостаточное количество спутников, плохая геометрия созвездия и т. п.). Несмотря на ряд преимуществ методов определения координат в режиме реального времени (RTK), постобработка не утратила своего значения и может быть востребована, если режим RTK не обеспечивает требуемую точность или необходимо получить некоторые дополнительные статистики (ковариационную матрицу, контраст, процент отбраковки).
 Программа Justin автоматически образует связи между перекрывающимися по времени интервалами наблюдений и формирует векторы, которые показываются в картографическом окне сразу после импорта файлов измерений в формате JPS (JAVAD GNSS) или в обменном формате RINEX. Данные статических наблюдений отображаются на карте отрезками прямых линий, а кинематических — траекториями в виде полилиний. Векторы также представляются в виде дерева связей в панели проекта, которое может быть использовано как альтернатива картографическому окну и удобно для запуска пакетной обработки группы векторов. Групповая обработка возможна и при указании нескольких векторов сразу с помощью инструмента «Выбор в прямоугольной области» в картографическом окне. Действия с векторами — обработка, получение информации, изменение свойств — осуществляются путем выбора объекта.
Программа Justin автоматически образует связи между перекрывающимися по времени интервалами наблюдений и формирует векторы, которые показываются в картографическом окне сразу после импорта файлов измерений в формате JPS (JAVAD GNSS) или в обменном формате RINEX. Данные статических наблюдений отображаются на карте отрезками прямых линий, а кинематических — траекториями в виде полилиний. Векторы также представляются в виде дерева связей в панели проекта, которое может быть использовано как альтернатива картографическому окну и удобно для запуска пакетной обработки группы векторов. Групповая обработка возможна и при указании нескольких векторов сразу с помощью инструмента «Выбор в прямоугольной области» в картографическом окне. Действия с векторами — обработка, получение информации, изменение свойств — осуществляются путем выбора объекта.
В целом, вышесказанного уже достаточно, чтобы приступить к обработке данных ГНСС, получить решение и вычислить координаты.
Настройки постобработки статических измерений
Модуль обработки в ручном режиме вызывается указанием на вектор при выборе опции «Параметры обработки».
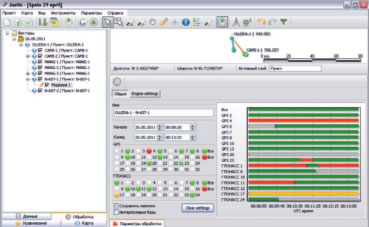
 Для настройки параметров обработки имеются два окна. Одно окно позволяет исключать спутники, ограничивать интервалы обрабатываемых измерений, запрещать использование спутника в качестве опорного. Другое окно предназначено для установки режимов обработки — выбора ионосферной и тропосферной моделей, угла отсечения измерений по возвышению спутника, установки метеопараметров, задания метода обработки, настройки стилей отображения решений на карте.
Для настройки параметров обработки имеются два окна. Одно окно позволяет исключать спутники, ограничивать интервалы обрабатываемых измерений, запрещать использование спутника в качестве опорного. Другое окно предназначено для установки режимов обработки — выбора ионосферной и тропосферной моделей, угла отсечения измерений по возвышению спутника, установки метеопараметров, задания метода обработки, настройки стилей отображения решений на карте.
По умолчанию установлен автоматический режим, при котором программа определяет способ обработки измерений, исходя из состава исходных данных, длины базисной линии, априорной статистической оценки результатов измерений. Если полученное в автоматическом режиме решение не удовлетворяет пользователя, то рекомендуется переходить к ручной обработке векторов.
В соответствии с обозначениями первые разности SD запишутся так:
- SD1 = Ф21 – Ф11 для 1-го спутника;
- SD2 = Ф22 – Ф12 для 2-го спутника;
- Ф — фазовые дальности от приемника до спутника.
Вторые разности DD запишутся так:
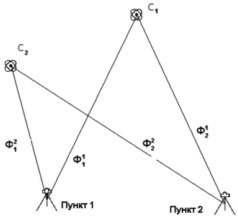 В соответствии с обозначениями пункт 2 будет считаться определяемым, пункт 1 — известным. Соответственно, спутник С1 будет опорным. Фазовые дальности известны с точностью до десятых долей миллиметра, но имеют фазовую неоднозначность N, что приводит к искажениям дальности, равным N*λ, где λ — длина волны. Кодовые дальности лишены неоднозначностей, но их точность 2–5 м.
В соответствии с обозначениями пункт 2 будет считаться определяемым, пункт 1 — известным. Соответственно, спутник С1 будет опорным. Фазовые дальности известны с точностью до десятых долей миллиметра, но имеют фазовую неоднозначность N, что приводит к искажениям дальности, равным N*λ, где λ — длина волны. Кодовые дальности лишены неоднозначностей, но их точность 2–5 м.
Алгоритм обработки выбирает в качестве опорного наиболее высокий на начальный момент спутник и старается сохранить его до тех пор, пока угол возвышения удовлетворяет некоторому критерию или же этот спутник пропадает из зоны видимости.
Представим ситуацию, когда наблюдения проводятся под кроной дерева. В этом случае наиболее высокий спутник будет мелькать за листвой, и указанный выше критерий выбора становится неоправданным. Поскольку выполняется предварительный анализ вторых разностей, каждая из которых включает опорный спутник, то большое количество эпох может быть отбраковано уже на начальном этапе из-за выявления грубых ошибок. В дополнение к этому, осложняется исследова ние непрерывности фазовых дальностей (cycle slips). Как следствие, решение получается недостаточно точным или вовсе отсутствует. Запрет на использование спутника в качестве опорного часто помогает существенно улучшить решение. Чтобы запретить использование спутника в качестве опорного, следует указать на него в диалоговом окне и установить «forbidden». Значок спутника изменится с «кружка» на «крестик». Определить, какой спутник был использован в качестве опорного, можно по графику остаточных уклонений. Этот график позволяет выделить данные, которые имеют остаточные отклонения, превышающие утроенную среднюю квадратическую погрешность (СКП) решения, или же имеющие тренды.
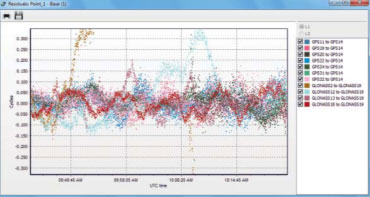 В программе реализована возможность многократной обработки вектора при различных установках. При этом все решения сохраняются и показываются на карте. Целью подбора интервалов является повышение контрастности решения и снижение процента отбракованных данных. Однако, исключая данные из обработки, не нужно забывать, что при малом числе измерений оценки решения, как правило, улучшаются, но становятся менее надежными. Поэтому при количестве спутников меньше шести не рекомендуется слишком полагаться на высокое значение контраста или малую СКП решения. Необходимо следовать известному правилу, определяющему, что интервал наблюдений в минутах должен быть равен длине линии в километрах плюс 5 минут. В таком случае контраст решения, полученного по данным, собранным в более или менее благоприятных условиях, не должен быть менее 95%, а отбраковка — не более 10%.
В программе реализована возможность многократной обработки вектора при различных установках. При этом все решения сохраняются и показываются на карте. Целью подбора интервалов является повышение контрастности решения и снижение процента отбракованных данных. Однако, исключая данные из обработки, не нужно забывать, что при малом числе измерений оценки решения, как правило, улучшаются, но становятся менее надежными. Поэтому при количестве спутников меньше шести не рекомендуется слишком полагаться на высокое значение контраста или малую СКП решения. Необходимо следовать известному правилу, определяющему, что интервал наблюдений в минутах должен быть равен длине линии в километрах плюс 5 минут. В таком случае контраст решения, полученного по данным, собранным в более или менее благоприятных условиях, не должен быть менее 95%, а отбраковка — не более 10%.
Добавим несколько слов об обработке коротких линий, длина которых не превышает 3 км. В этом случае можно рассчитывать на то, что вычислительный алгоритм позволит получить точное решение уже по единственной эпохе. Контраст решения может быть при этом невысоким, порядка 75–80%, что не дает уверенности в надежности решения. Чтобы снять вопрос о достоверности полученного результата, рекомендуется разбить весь интервал наблюдений на несколько частей, обработать их по отдельности и сравнить решения.
Выше мы рассмотрели возможности улучшения статистик решения путем подбора измерений. Теперь остановимся на выборе оптимального алгоритма обработки, который предоставляет опытному пользователю не менее широкие возможности получения хорошего решения. Напомним, что кодовые и фазовые дальности определяются спутниковыми приемниками на двух частотах GPS или ГЛОНАСС. Гражданский CA и военный P-код GPS имеют разную энергетику, поэтому измерения различаются по точности. Если исходные данные получены при импорте файлов JPS, то они однозначно идентифицируются. В случае загрузки файлов в формате RINEX, полученных конверторами сторонних фирм, отличить данные СА и Р кодов не всегда возможно, так как они могут замещать друг друга. Инициализация весов становится не объективной, а их корректировка на основании анализа остаточных уклонений решения по методу наименьших квадратов часто приводит к дисбалансу влияния отдельных данных на окончательное решение. Пороговые значения соотношения весов измерений на обеих частотах, хотя и подбираются разработчиком алгоритмов, исходя из критериев нормального распределения ошибок, но все же сильно зависят от правильной идентификации исходных данных.
Автоматический режим получения решения выполняется по следующему сценарию: на основе первичной обработки кодовых измерений (псевдодальностей) вычисляются приближенные компоненты вектора, проводится отбраковка грубых измерений, оценивается точность, определяются ионосферные задержки, уточняются тропосферные поправки, составляется ковариационная матрица.
Следующим шагом приближения для двухчастотных данных является так называемое решение Wide Lane, для которого составляется комбинация фазовых измерений на первой и второй частотах ФWL = (ФL1/λ1 – ФL2/λ2)λWL, λ1≈ 19 см, λ2≈ 24 см, λWL≈ 86 см, Ф — вторые разности. Линейная комбинация Wide Lane состоит из измерения на различных частотах, которые в общем случае имеют различную точность, следовательно, преимущество более высокоточных данных теряется. Другая проблема решения Wide Lane заключается в том, что измерения по первой и второй частотам часто не совпадают между собой по времени, поэтому часть данных пропадает. Несмотря на целый ряд недостатков, решение Wide Lane может быть полезно, так как при длине волны 0,86 м и точности кодового решения менее 0,5 м неод нозначности Wide Lane определяются достаточно легко. Получив эти значения и учитывая, что NWL = N1 – N2, легко перейти к определению неоднозначностей по первой частоте, объединив уравнения, составленные как по первой частоте ФL1, так и по второй, но исправленной следующим образом:
Для модифицированных данных второй частоты величина NL2 = NL1, поэтому число неизвестных новой системы уравнений будет равно числу неизвестных Wide Lane, а количество уравнений вдвое больше. Завершением автоматической обработки данных является решение, полученное по так называемой комбинации Narrow Lane, ФNL = (ФL1/?λ1 + ФL2/λ2)λNL, λNL≈ 10 см, и комбинации, учитывающей ионосферную компоненту.
Решение L1&L2 основано на одновременном вычислении неоднозначностей по первой и второй частотам и, в отличие от решений, связанных с комбинациями данных, позволяет, во-первых, использовать все имеющиеся данные, а во-вторых, наиболее эффективно при уточнении весов путем последовательных приближений. Хорошей проверкой обоснованности применения режима L1&L2 является отдельная обработка в режимах L1 и L2. В случае, когда два пос? ледних метода дают приемлемое решение, следует ожидать более высокую точность варианта L1&L2. Основными ограничениями метода L1&L2 на этапе определения неоднозначностей является неточность оценки поправки, определяемой с помощью навигационной информации по ионосферной модели ИКД (интерфейсный контрольный документ). В свою очередь, определение параметров ионосферы параллельно с решением может быть приемлемо только на достаточно большом наборе данных. На расстояниях свыше 15 км или в условиях активной ионосферы (дневной период летом) ионосферное влияние на двойные разности приводит к осцилляциям и трендам, превосходящим длину волны, и поэтому большое количество данных бракуется. Окончательным этапом обработки в режиме L1&L2 является решение, полученное на основе формирования свободной от ионосферы комбинации.
Первые разности фазовых измерений имеют меньшую шумовую составляющую. Определив вторые разности, легко перейти к решению, основанному на первых разностях. Введем поправки в измерения в соответствии с формулой:
где Ф
DD — вторые разности, N
DD— полученные неоднозначности вторых разностей, λ — длина волны. Теперь остается только заново решить систему уравнений, в которой количество неизвестных неоднозначностей уменьшится до одной.
Завершая описание модуля обработки, отметим, что в случае использования точных эфемерид вместо навигационных, необходимо импортировать файлы sp3 форматов b/c не только на день наблюдений, но и на две соседние даты.
Настройки постобработки кинематических измерений
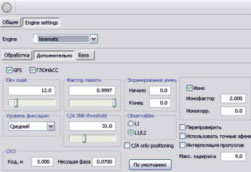 Модуль ручной настройки обработки кинематических данных вызывается при указании на траекторию и выборе соответствующего пункта меню.
Модуль ручной настройки обработки кинематических данных вызывается при указании на траекторию и выборе соответствующего пункта меню.
В числе настроек постобработки, смысл которых достаточно очевиден, выбор систем GPS/ГЛОНАСС, задание критерия выбора спутников по углу возвышения и по азимуту, установка порогового значения сигнал/шум, точных или навигационных эфемерид, возможность отключения данных, полученных по второй частоте, интерполяция решений на эпохи, где отсутствуют данные.
Некоторые параметры требуют отдельного пояснения. Фактор памяти определяет скорость «забывания» результатов, полученных в предыдущих эпохах. Это может быть существенным в высокодинамичных приложениях. Пример эффективности критерия авторы наблюдали при сопровождении проекта, связанного с обработкой траекторий на горнолыжных трассах в Альпах. Рекомендуемые значения величины «Ионофактор» варьируются в диапазоне от 2 до 4, что соответствует состоянию ионосферы от спокойной до возмущенной. Большее значение величины «Ионофактор» расширяет границы допустимых значений остаточных уклонений. Соотношение СКП для кодовых и фазовых измерений можно изменять таким образом, что вес фазовых данных возрастет относительно кодовых, и процент фиксированных решений увеличится, но при этом также возрастет вероятность ошибочной фиксации.
В заключение заметим, что предусмотрена возможность изменения типа данных со статического на кинематический и наоборот. Следовательно, для статических данных будут получены решения на каждую отдельную эпоху, а для данных, которые первоначально были определены как кинематические (например, полученные в режиме «Стой-Иди», или же выборки отдельных интервалов кинематических траекторий), можно добиться надежного статического решения.